A not-so-costly way to High Performance Computing
Most of us with scientifically inclined mind get thrilled just by the idea of having a supercomputer or a massive cluster at our disposal, hidden in a dark room somewhere in the basement of our home. Here is a picture just to feed your wild imagination!

But don’t get too carried away guys, as unfortunately we all know that’s not gonna happen anytime soon, if at all. Good news though is that we “almost surely” don’t need that much processing power. So, the question is, can our imagination come true at least to some extent? Is there some way that we can have a really powerful machine at our disposal whenever we need? Well, the answer is yes there is a way, but it will cost you a little. Whether you can afford it will depend on two things - how long you want to access it and how much processing power you want your machine to have. This is what I am gonna talk about in this and a few follow up posts that will help you decide if the solution works for you and if yes, how to set up such a system.
Now, let me get to the real story that inspired me to put up this topic. If you are into data science, you most likely know about the website Kaggle already, which hosts data science competitions. If you don’t, but interested in data science, it might be worthwhile to spend some time on it. While searching for interesting problems a few days ago, I stumbled upon an image classification challenge in that website. I shall describe the problem very briefly here for the sake of completion. The objective of the challenge is to predict protein organelle localization labels. Don’t be afraid, it is not as difficult as it sounds, let me explain. Eukaryotic cells are divided into subcellular compartments or organelles. Probably a video might help you here,
These cells can synthesize up to 10,000 different kinds of proteins, which all are destined for one or more pre-determined target organelles. Transporting these proteins to the correct final destination is therefore crucial. In order to completely understand this process, we need to have some way to localize proteins in different organelles, which is called protein organelle localization. Here is a picture from the Cell Atlas, to help you visualize how proteins are localized to different subcellular organelles and substructures in a cell.
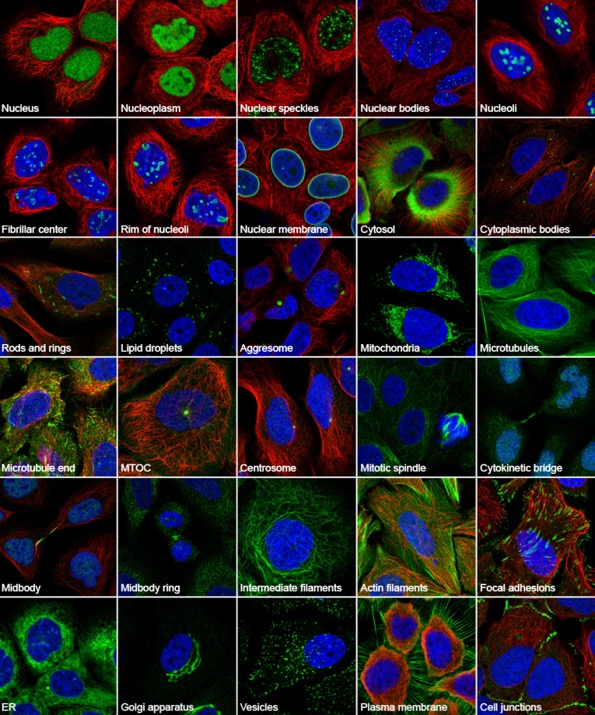
In the challenge, we are trying to automate this process of localizing proteins to at least one organelle (labeling) using machine learning techniques and hence the name - prediction of protein organelle localization labels. The goal is to have some model, which takes a cellular image as an input and will predict the organelle localization labels for the protein as output. Hopefully, everyone has grasped the essence of the problem by now.
Moving on, let’s talk about the computing power needed to tackle this kind of problems. There are more than 50,000 images to train our classification model, each image being a 512x512 PNG file. So, assuming each image to be in black and white (not completely true by the way), it will take 512 x 512 x (1 Byte) = 256 kBytes for each image. So, in total at least (50000 x 256kB) / (1024 x 1024) = 12 GB of raw image data is to be processed to train the model. Furthermore, a little research revealed that all the top performing teams are using deep learning algorithms to train their models. At this point, I was getting a little frustrated, as training a sufficiently deep network takes a lot of time (days), and as it turned out a few teams were using their own equally big datasets in addition to what was already provided to get even better models. So, it is nearly impossible to compete with these teams if I can’t get access to a really high performance machine and when I say high performance I don’t mean 8-core or 12-core machines but those with hundreds of cores. But, there is a catch here. You don’t need to have a massively parallel CPU-based system if you have a powerful GPU (Graphics Processing Unit) at your disposal and here is why. GPUs were first developed for handling computer graphics tasks like image processing, video rendering. These kind of jobs consist of simple operations which can be performed in a very parallel fashion on image data. To tackle this inherent parallelism, GPUs were designed to have thousands of processing cores running simultaneously (based on SIMT Architecture: single instruction multiple thread). On the other hand CPUs have very few cores with higher clock speed, are more flexible with capability of handling a wider range of tasks which are more sequential in nature. Here is a fun demonstration by the Mythbusters,
So, if your buddy is a pro gamer with powerful graphics card (contains one or more GPUs), and you wanna compete in this kind of data science challenges, you got to figure out a way to access those. Well, your plan would better be creative than violent, otherwise you run at risk of losing your buddy or even worse! Once you have it, you are the champion! Just kidding, its not that simple though. ;-) Unfortunately I don’t have such a buddy to persuade. Lucky for me, I got Google to help me get out of this situation. I started searching for cloud computing services and found Google Cloud Compute Engine to be a potential solution to my problem. With the help of Google compute engine, you can create a monstrous system with 96 CPUs (dual core), 624GB RAM, SSD with almost as much space as you can think of and 8 extremely powerful NVIDIA V100 Tensor Core GPUs. This kind of configuration will cost a lot for sure, so it’s better to not get too greedy and choose a configuration that seems right to tackle the problem at hand, otherwise it will be a complete wastage of money as well as computing resources.
Thus, Google Compute Engine gave me a way to tackle the deep learning problem I was trying to solve. I hope you guys want to know more about it, but I got to stop here to make the post not too lengthy. In the follow up post I shall talk about the google compute engine in detail, different configurations it offers, pricing policies etc. So, that’s it for now, see you in the next post!